
You think you’re having a conversation with ChatGPT or Claude. You type a question, it gives you an answer, and you ask a follow-up question. Feels pretty natural, right?
What’s happening under the hood is nothing like a conversation. Understanding the probabilistic inference that generates those confident-sounding responses changes everything about how you should use these tools.
Tokens: The Lego Blocks You Never Knew Existed #
First, forget about words. LLMs don’t see words. They see tokens.
When you type “I love tokenization,” the model breaks it down: “I”, " love", " token", “ization”. A token might be a whole word like “cat” or a fragment like “ization” or “ing”. Common words become single tokens. Long or unusual words get chopped up. Even spaces and punctuation count as tokens.
It’s a compromise between vocabulary size and computational efficiency as most models use vocabularies of 50,000 to 200,000 tokens.
The Inference Engine: One Token at a Time #
When an LLM generates a response, it’s not thinking through what it wants to say. It’s predicting one token at a time, based on everything that came before.
The model calculates probability distributions across its entire vocabulary. Every token gets a probability score. Then it samples from that distribution.
My friend Eugene Meidinger wrote a tool to visualize token usage and gave me this image as an example for one of my previous blog posts, but I think it fits very well here:
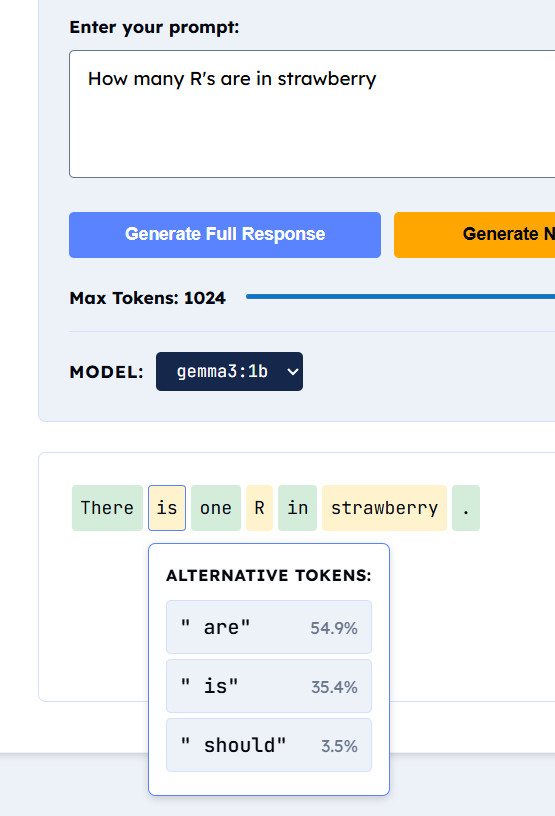
It doesn’t just pick the most likely token. That would make responses boring and repetitive. Instead, it samples with controlled randomness. Parameters like “temperature” adjust the randomness - high for creativity, low for predictability.
This is why the same question twice gets different answers. Each token draws from a weighted probability distribution. The model predicts a token, adds it to the sequence, then predicts the next one.
Edit: As Joey D’Antoni very correctly pointed out, this is also why LLMs very rarely cache anything - the compute cost is way too high.
The model has zero concept of what it’s going to say until it says it. And somehow, this produces coherent paragraphs and logical arguments - or what looks like them.
The Reasoning Simulation Paradox #
Despite token-by-token generation without planning, these models reliably produce structured arguments and maintain logical consistency. They’re not “thinking ahead,” but the statistical patterns they’ve learned encode reasoning structures.
When Claude writes “Let me break this into three parts: first, second, third,” it’s not because it planned a three-part structure. Training data contains countless examples of that pattern, and the token sequence reinforces itself.
The autoregressive process (where each token conditions on everything before it) simulates reasoning through sequential inference. The model exhibits multi-step reasoning without possessing intent. In plain english: it sounds like intent, but there is no intent. There is a huge difference.
This relates to my “Untruthful Art” presentation - these models can produce graphs and arguments that look reasoned without any actual reasoning. Patterns from training data create outputs that exhibit reasoning structure, making them perfect tools for producing exactly the misleading-but-convincing visualizations I warn about.
Images: Everything Becomes Tokens #
You’d think images would work differently? Not at all. Modern models like GPT-4 and Claude convert images into tokens too.
A vision encoder analyzes your image and produces a sequence of image tokens representing colors, shapes, textures, and spatial relationships. A single image becomes hundreds or thousands of tokens. Those image tokens flow through the same transformer architecture that processes text.
All tokens, same mechanism. You can imagine what that means when even just a few pixels differ in two images. Different tokens, potentially different results.
The catch? Images are expensive. A high-resolution image can consume as many tokens as several paragraphs of text. That’s why models limit image sizes - you’re consuming a substantial portion of your context window.
The English Bias Nobody Wants to Talk About #
Most LLMs are fundamentally less effective for non-English languages. It starts with tokenization.
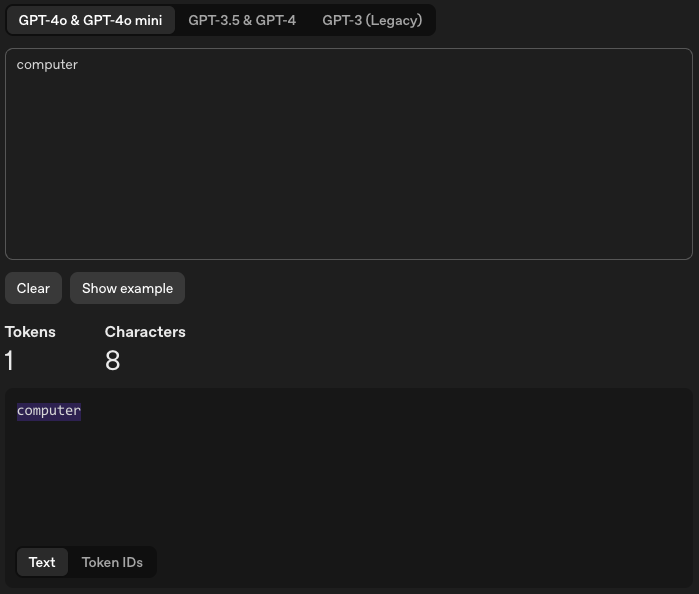
These tokenizers were trained primarily on English. English gets an efficient token representation. “Computer” is one token. English text flows at roughly one token per 0.75 words.
Switch to Swedish? Everything changes. “Datorkunskap” (roughly translated to computer knowledge or computer science) fragments into multiple tokens because the tokenizer never saw much Swedish during training. Japanese uses three to four times as many tokens as equivalent English.
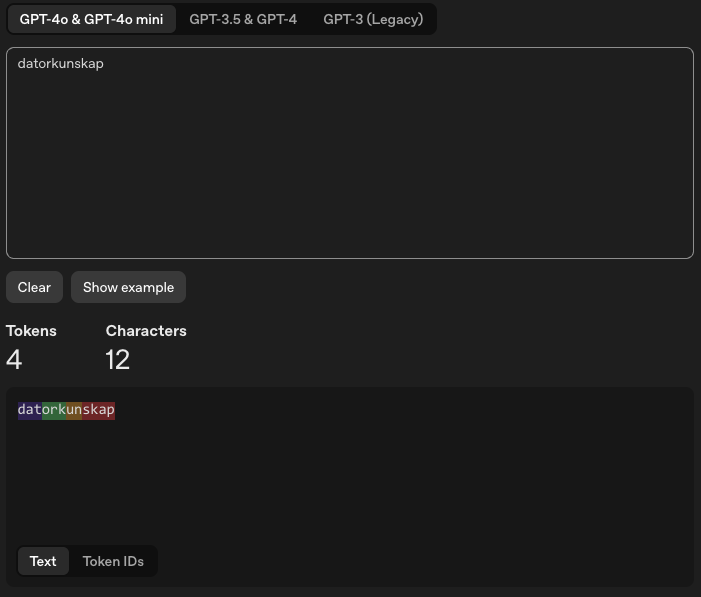
More tokens means degraded performance. When “datorkunskap” fragments into [‘dat’, ‘ork’, ‘un’, ‘skap’], the model maintains attention weights across four tokens instead of one. Over a 500-token Swedish conversation, you’ve multiplied attention complexity while shrinking the effective semantic window. Remember: the model tracks fragments, not concepts.
English: “The computer program failed” = 4 tokens
Swedish: “Datorprogrammet misslyckades” = ~8 tokens
The model processes 60-100% more token transitions for identical semantic content.
I see this constantly in Swedish technical work. Less fluent text, more grammatical errors, lost threads in complex arguments, accidental code-switching to English because some of the tokens look like English, and that’s where training density lives.
This is entirely solvable: train tokenizers on multilingual data evenly or use language-specific tokenizers. But that adds complexity and cost. Companies optimize for English and accept degraded performance everywhere else.
If you’re working in Tamil, Arabic, Korean, or hundreds of other languages, you’re getting a fundamentally inferior product. Most users don’t even realize the performance gap exists.
The Ouroboros Problem: When AI Eats Its Own Tail #
As AI-generated content proliferates online, it inevitably becomes training data for future models. What happens when LLMs train on outputs from predecessors? Model collapse: a degenerative process where models progressively lose their ability to generate diverse, high-quality outputs.
In early model collapse, models lose information from distribution tails - rare but important edge cases that maintain model accuracy and output variance. This is insidious because overall performance may appear stable while the model quietly loses its ability to handle uncommon scenarios.
In late model collapse, degradation becomes obvious: models confuse concepts, produce repetitive or nonsensical output, and lose most variance. In one experiment, an LLM fine-tuned on successive generations of its own output started with medieval architecture text and by the ninth generation was producing nonsensical jackrabbit lists.
This happens because generative models don’t perfectly replicate the original data distribution - each generation introduces errors. When errors compound across training cycles, the model’s understanding drifts from the actual data distribution. Probable events get overestimated, improbable events disappear, and the model becomes poisoned with its own projection of reality.
The internet is becoming an Ouroboros: models trained on web-scraped data will inevitably train on increasing synthetic content. Researchers predict we could run out of fresh human-generated training data between 2026 and 2032. Take a look at a calendar. 2026 is very close.
Recent research offers hope: if synthetic data accumulates alongside real human data rather than replacing it, model collapse can be avoided or slowed. Careful curation and verification before training can also prevent the worst effects.
But companies with large pre-2022 datasets (before generative AI proliferation) now possess an increasingly valuable resource. The window for collecting uncontaminated human-generated data is closing, potentially making the current AI players even more dominant.
What This Actually Means for You #
If you’re a developer working with LLM APIs, you’re paying per token. English users get more value per dollar. Your costs scale non-linearly in non-English languages, and performance degrades faster as conversations lengthen.
For everyone else: these systems aren’t magic. They’re pattern-matching engines with sampling-based generation, trained primarily on English, producing output token by token without knowing where they’re going. And they’re increasingly training on their own outputs, with all the risks that entails.
They’re not thinking. They’re not reasoning in the human sense. They’re performing statistical inference across learned patterns, sampling from probability distributions at every step, somehow producing text that exhibits reasoning patterns and feels human.
That’s impressive. Genuinely remarkable technology. But it’s not intelligence as we typically mean it. It’s not consistent. It’s not immune to degradation through recursive training. And it’s definitely not something you should trust blindly.
Next time you’re chatting with Claude or ChatGPT, remember: under that conversational interface is a probabilistic inference engine - statistically grounded, mathematically precise, and fundamentally non-deterministic.
To add to this, I’d like to end with a small, ominous reflection. Humans have a remarkable way of seeing and adapting to patterns. If something behaves in a specific way a few times, the brain adapts and conditions us to expect the same pattern. If an LLM gives you good advice on something a few times, you are conditioned to expect the same good advice in the future too - even to the point of trusting the output of the LLM (the pattern) more than your own judgement.
Understanding that changes everything.
Join the Conversation #
What’s your experience with LLMs? Has understanding their internals changed how you use these tools? Reach out to me or comment on LinkedIn or BlueSky!
References #
Tokenization & Subword Units #
Sennrich, R., Haddow, B., & Birch, A. (2016). “Neural Machine Translation of Rare Words with Subword Units.” Proceedings of ACL. https://aclanthology.org/P16-1162/
Kudo, T. & Richardson, J. (2018). “SentencePiece: A simple and language independent subword tokenizer and detokenizer for neural text processing.” EMNLP System Demonstrations. https://aclanthology.org/D18-2012/
Rust, P., et al. (2021). “How Good is Your Tokenizer? On the Monolingual Performance of Multilingual Language Models.” Proceedings of ACL-IJCNLP. https://aclanthology.org/2021.acl-long.243/
Ahia, O., et al. (2023). “Do All Languages Cost the Same? Tokenization in the Era of Commercial Language Models.” EMNLP. https://arxiv.org/abs/2305.13707
Transformer Architecture & Autoregressive Generation #
Vaswani, A., et al. (2017). “Attention Is All You Need.” NeurIPS. https://arxiv.org/abs/1706.03762
Radford, A., et al. (2019). “Language Models are Unsupervised Multitask Learners.” OpenAI Technical Report. https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
Temperature & Sampling Strategies #
Holtzman, A., et al. (2020). “The Curious Case of Neural Text Degeneration.” ICLR. https://arxiv.org/abs/1904.09751
Renze, M., et al. (2024). “The Effect of Sampling Temperature on Problem Solving in Large Language Models.” arXiv:2402.05201. https://arxiv.org/abs/2402.05201
Model Collapse & Synthetic Data #
Shumailov, I., et al. (2024). “AI models collapse when trained on recursively generated data.” Nature, 631(8022), 755-759. https://doi.org/10.1038/s41586-024-07566-y
Gerstgrasser, M., et al. (2024). “Is Model Collapse Inevitable? Breaking the Curse of Recursion by Accumulating Real and Synthetic Data.” arXiv:2404.01413. https://arxiv.org/abs/2404.01413
Feng, Y., et al. (2024). “Beyond Model Collapse: Scaling Up with Synthesized Data Requires Verification.” arXiv:2406.07515. https://arxiv.org/abs/2406.07515
Feng, Y., et al. (2024). “A Tale of Tails: Model Collapse as a Change of Scaling Laws.” ICML. https://icml.cc/virtual/2024/poster/33678
General LLM Behavior #
Brown, T., et al. (2020). “Language Models are Few-Shot Learners.” NeurIPS. https://arxiv.org/abs/2005.14165
Wei, J., et al. (2022). “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.” NeurIPS. https://arxiv.org/abs/2201.11903
Additional Resources #
- HuggingFace Tokenizers Documentation: https://huggingface.co/docs/tokenizers/
- OpenAI Tokenizer Tool: https://platform.openai.com/tokenizer
Photo by Armando Are: https://www.pexels.com/photo/purple-dices-with-different-geometrical-shape-on-a-white-surface-3649115/